Attention Is All You Need 笔记
1. 背景
在解决翻译问题时,如果句子长度过长 Encoder-Decoder 的模型也不能得到良好的结果。这样的问题就是长序列会遇到的问题,其主要原因是序列过长时,向后处理序列时前面的序列会出现“遗忘”问题。通过 Attention 的方式可以缓解这种问题,增加长记忆的能力。
RNN 存在的问题之一,不能并行化——即 $t$ 时刻结果序列需要依赖于 $t-1$ 时刻前的所有输入序列。虽然 CNN 可以进行并行化计算,但 CNN 也存在缺点:1)是在序列模型中,只能考虑到 $kernel-size$ 大小的序列,而不能进行全局考虑;2)当然可以通过 CNN 叠加的方式,实现在上层网络输出一定程度上考虑更长的信息。需要的网络复杂性较大,才能进行全局信息。


2. 模型机制
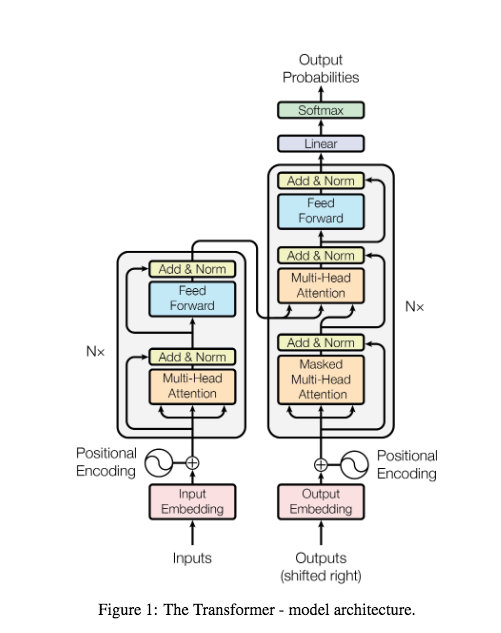
self-attention 解决了全局信息需求的同时,而且可以进行并行化运行。结构上还是参考了 Encoder-Decoder 结构,其中 Encoder 使用叠加六个相同结构的 layer,其中使用了多头注意力机制: 三个重要的变量 $Q$ 查询,表示需要匹配其他的对象;$K$ 键,需要用于被匹配的对象;$V$ 提取出的信息。
2.1 Positional Encoding 细节
self-attention 天然并未解决输入的位置关系问题,其计算过程是并行化计算不依赖于上一个 token 的输出(而 RNN 是具有一定前后序列关系)。为了加入 Token 的位置顺序,论文中加入了 positional encoding 的方法来解决位置因素——添加的信息考虑到绝对位置。
模型中的位置信息是在输入和输出的 Embedding 中添加上 Positional Encoding,根据奇偶位置采取正弦和余弦函数得到编码的数据值:
$$
PE_{(pos, 2i)}=\sin(\frac{pos}{10000^{2i/d_{model}}}) \
PE_{(pos, 2i+1)}=\cos(\frac{pos}{10000^{2i/d_{model}}})
$$
其中 $pos$ 表示为位置,而 $i$ 是表示维度(representation dimension,对应的值是在 $d_{model}$ 中的位置)。以该方式得到相关的位置信息,进行可视化展现出位置以及维度影响:

从第二张图可以看出这种序列顺序,通过这种差异表现出来,而且从第一张图可以看出这种关系具有一定的周期性(论文中阐述到这种周期性长度从 $2\pi$ 到 $1000\cdot 2\pi$)。Positional Encoding 的应用是将其值和 Embedding 值相加即引入了顺序值。
2.2 多头注意力机制
2.2.1 scale dot product attention
通用的 attention 结构包括包括 additive 模式和 multiplicative 模式,而在论文中采用了 scale dot product attention,数学表达式为 $\text{Attention}(Q,K,V)=\text{softmax}(\frac{QK^T}{\sqrt{d_k}})V$,其中 scale 的步骤是通过 $\frac{1}{\sqrt{d_k}}$ 完成——它的作用也是避免高维度点积处理 softmax 之后梯度过小的问题。
将整个 sequence 作为输入,self-attention 的流程如下:

在生成 $Q$、$K$ 和 $V$ 的等式中各个 $W$ 对应的输入 token 都是共享的。上图在论文中的模型结构如下:

2.2.2 Multi-Head Attention
论文中引入了 $h$ 个对 $Q、K、V$ 的并行化计算的映射取得了较好的效果,这样的好处类似于能够得到更多的注意力信息。拆开来看多头类似于下图中(下图只是使用了两个 head),将使用原有的一套 $Q、K、V$ 变为了两套——需要注意每一套内部相关联计算,而不是交叉计算。

多头生成的结果使用了 concat 拼接的方式得到结果,之后将拼接的结果进行了线性变换以实现降维度目的。最终的数学表达式为 $\text{MultiHead(Q,K,V)}=\text{Concat}(\text{head}_1,\cdots,\text{head}i,\cdots,\text{head}_h)W^O$,其中 $\text{head}_i=\text{Attention}(QW_i^Q,KW_i^K, VW_i^V)$,$W^O$ 是一个 $\mathbb{R}^{hd_v \times d{model}}$ 的矩阵。Multi-Head Attention 的结构如下:

2.2.3 Encoder 和 Decoder 其他细节
在两个 Block 中均存在残差网络和 Layer Normalization,此外在 Decoder 的 Block 中有两次多头处理,而且在第一层多头中添加了 Mask 处理。
- 残差网络可以在增加网路深度时,能够维持梯度存在以避免深度过深而梯度消失
- Layer Normalization 可以类比于 CNN 中对 Channel 的维度方向上进行 Normalization,而在这里使用是为了保持 Tokens 在多个序列上缩放
- 使用 Mask 是因为在训练过程中,添加了后续数据的位置信息(在 Positional Encoding 是添加上的),需要避免在在预测时结果序列数据完全未知,因此需要在训练阶段将未参与的位置信息屏蔽掉
备注
-
Transformer 实现细节
Transformer: A Novel Neural Network Architecture for Language Understanding
Google 博客对 Transformer 解释
Attention Is All You Need 笔记
https://zenray.github.io/[object%20Object]/%E8%AE%BA%E6%96%87-AttentionIsAllYouNeed/